
What Happened to Fog Computing? Fog vs. Edge Explained
For several years, fog computing was promoted as a powerful bridge between the cloud and devices at the edge. It promised to reduce latency, make networks more efficient, and prepare industries for the explosion of IoT devices. Yet if you look around today, the term “fog computing” is rarely used. Instead, edge computing dominates conversations about distributed computing. The difference comes down to simplicity, advances in technology, and how enterprises adapted to real-world requirements. This shift is often framed as fog computing vs edge computing, a comparison that highlights how the industry’s focus has evolved.
This article explores what fog computing was meant to achieve, how it differs from edge computing, and why the industry shifted its focus. We will also look at the role both concepts play in modern application orchestration and where the future of distributed computing is heading.
The Evolution of Cloud vs Fog vs Edge Computing
To understand the role of edge, fog, and cloud computing, it is helpful to look at how the concepts evolved over time and what the differences are.
In the early days of cloud adoption, data collection within enterprise premises was simple:
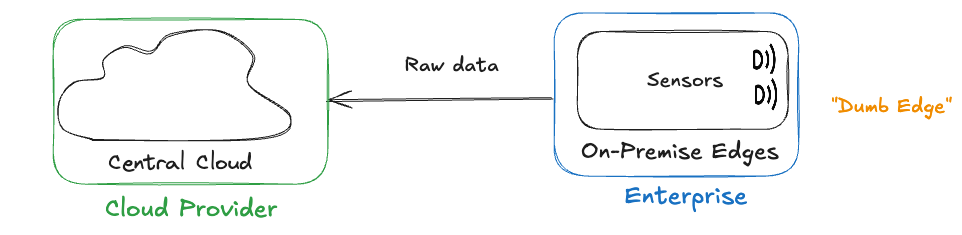
Sensors and applications generated raw data, which was shipped in full to the cloud for processing. At this stage, the edge as we know it today did not exist. All compute operations happened in centralized cloud data centers. This led to predictable problems: high bandwidth usage, increased costs, and unacceptable latency for real-time use cases.
Enter “Fog Computing”
To address these shortcomings, the idea of fog computing emerged around 2012, introduced by Cisco.
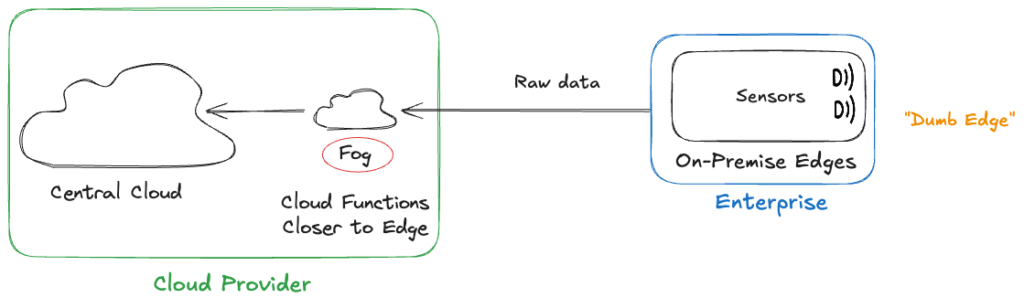
Fog placed an aggregation layer between the enterprise and the cloud, hosted in routers, gateways, or base stations. This was largely driven by cloud and telecom providers, who envisioned fog as a network-centric extension of their infrastructure. The commercial narrative positioned fog as cloud-managed edge, still under the service provider’s umbrella.
The Rise of Edge Computing
In parallel, edge computing started evolving in enterprises. Instead of sending all data outward, compute moved as close to the source as possible — within factories, stores, and other local environments.
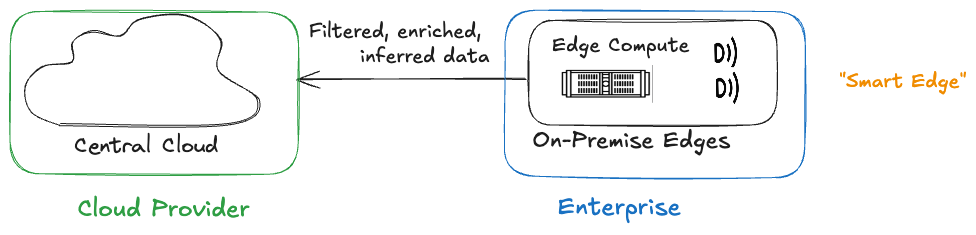
This approach drastically reduced bandwidth requirements while enabling low-latency, real-time decisions. Unlike fog, edge computing was enterprise-owned and operated, aligning with operational needs like resilience, compliance, and data sovereignty.
“Gartner projects that by 2025, over 50% of enterprise-generated data will be handled at the edge,”
indicating that modern edge platforms are becoming intrinsically smarter, as they transform from mere collectors to agile, intelligent compute hubs.
Where Are We Today? Edge Computing vs. Fog Computing
The term fog is rarely used today, but that doesn’t mean aggregation layers disappeared. Instead, they are described differently and implemented with other technologies:
- Within enterprises:
- Small on-premise data centers.
- Layered edge architectures (e.g., per-machine edge nodes feeding into a factory-level aggregation system).
- From cloud providers:
- Cloud infrastructure placed closer to users than central regions — called regions, local zones, outposts, or edge zones.
Quick Comparison: Fog Computing vs. Edge Computing: What’s The Difference
| Aspect | Fog Computing | Edge Computing |
| Definition | A decentralized computing infrastructure that extends the cloud to the edge of the network. | Processing data at or near the source of data generation |
| Location in hierarchy | Positioned between the cloud and edge devices | At or very near the device where data is generated |
| Scope | Aggregates and processes data from multiple devices before cloud transmission | Handles processing for individual devices or small clusters |
| Data processing | Provides filtering, caching, and pre-analysis before cloud upload | Provides immediate, real-time processing at the device level |
Why Fog Faded and Edge Computing Took Over
When Cisco first introduced the concept of fog computing in 2014, it generated significant excitement. It seemed to offer a natural bridge between the cloud and the increasingly powerful devices at the edge. However, over the following years, edge computing emerged as the dominant paradigm. This raised an important discussion around edge vs fog computing, with enterprises weighing which approach delivered the most practical benefits.
There are several reasons why fog computing lost traction:
- Simplicity of edge computing: Adding a fog layer increased architectural complexity. Many organizations found it easier and more efficient to run workloads directly at the edge rather than maintain an extra layer of nodes.
- Advances in hardware: Microcontrollers, GPUs, and specialized AI chips made edge devices smarter and more capable of handling workloads that once required intermediate processing.
- Rise of 5G: High-speed, low-latency networks further reduced the need for fog. With reliable connectivity, edge devices could communicate with the cloud more efficiently.
- Real-time requirements: Industries such as automotive, healthcare, and industrial automation needed instant responses that only true edge computing could provide.
While the word fog has faded from mainstream use, the architectural concept of intermediate aggregation is still very much alive. Enterprises implement it with layered edge deployments and on-premise aggregation, while cloud and telecom providers deliver it through local regions and edge services.
In other words: fog didn’t disappear — it evolved into edge architectures and cloud extensions.
The shift from fog to edge also has implications for how applications are orchestrated across distributed environments. This makes the fog computing vs edge computing what’s the difference question especially relevant for enterprises designing future-ready systems.
How Edge Computing is Changing Application Orchestration
As the historic overview showed, the shift to edge computing means that edge nodes are no longer just pipes for forwarding data to the cloud. They have become application platforms that run critical workloads close to where data is created. Typical examples include real-time analytics on sensor streams, AI inference for vision or quality control, and integration services that connect machines with enterprise systems. This shift makes edge application orchestration a core requirement for building resilient and modern distributed architectures.
Application orchestration refers to the automated management of applications across multiple locations. In cloud computing, orchestration ensures that workloads are deployed, scaled, and maintained efficiently. But with thousands of edge devices now joining the mix, orchestration faces new challenges.
Modern orchestration tools, such as Kubernetes, were not originally built for edge environments. They assumed stable, centralized infrastructure.
Challenges include:
- Managing software across thousands of geographically dispersed devices.
- Ensuring security and updates in environments with intermittent connectivity.
- Balancing performance between centralized cloud systems and local edge workloads.
Solutions are emerging in the form of specialized edge orchestration platforms. These extend the principles of container orchestration into highly distributed networks. Companies can now deploy, monitor, and update applications at the edge with the same consistency they enjoy in cloud environments.
For a deeper exploration, see Avassa’s guide on distributed edge application orchestration.
Conclusion: The Future is Everywhere
Fog computing was once promoted as the missing link between cloud and edge — an aggregation layer in telecom and network equipment that promised reduced latency and more efficient data handling. But the term never gained lasting traction in enterprises. Instead, edge computing became the dominant paradigm, fueled by simpler architectures, more powerful edge hardware, and the growing need for real-time, on-premise processing.
While the word fog has largely faded, its architectural idea of intermediate aggregation lives on. Enterprises implement it through layered edge setups and local data centers, while cloud providers offer variants such as local zones and edge regions.
This shift has direct implications for application orchestration. Edge nodes are no longer just data forwarders but application platforms hosting real-time analytics, AI inference, and integration services. Managing these workloads across thousands of distributed sites requires specialized edge orchestration platforms — extending the automation principles of the cloud to highly distributed and intermittently connected environments.
In short: fog didn’t disappear, it evolved into modern edge and cloud extensions — and orchestration is the key to making them work at scale.