
Why Offline Capabilities Matter in Edge Computing
The ability for applications to run without relying on the operational status of the upstream infrastructure is one of the key tailwinds for edge computing in our view.
Many companies put business-critical applications at the edge. Usually hosted on a small number of computers to support applications that need to run close to physical edges, i.e. near data sources and users. This pattern is common across many verticals including retail (computers in stores), industrial manufacturing (factory floors), and marine environments (on board ships).
But placing applications at the edge doesn’t in itself make them resilient throughout connectivity outages. In this article, we’ll break down the topic of offline capabilities.
Because There is Always That Guy
The main operational reasons, we find, to put applications at the edge is to avoid application downtime when the upstream infrastructure fails. And infrastructure failure is often because…

Outages obviously come in many shapes and forms, but a very common main factor is human error. While it is hard to formally delineate between human error and other types, some research shows that human error plays a role in about two-thirds of all outages.
So the challenge becomes one of designing the on-site edge infrastructure to make sure that the applications are kept whole and running despite that guy.
Why Edge Applications Fail Without Local Services
Most modern applications operationally depend on a suite of external services: secrets management, event and log streaming, name resolution, failover capabilities, and more. In centralized cloud environments, these services are available on a rack- or site-level often with two- or three-way redundant infrastructure between them. The result is that applications running in clouds rarely fail because they can’t reach the services they need for operations.
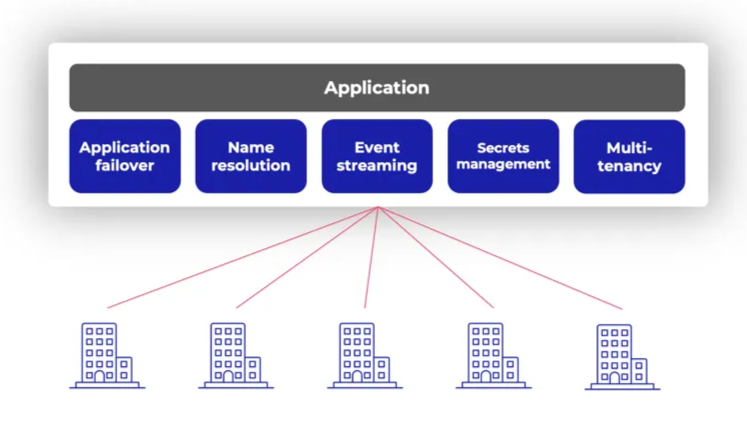
But what happens when you move applications to the edge and the upstream connection is lost? Without local versions of those same services, your containers won’t restart, your secrets can’t be fetched, and your application eventually grinds to a halt.
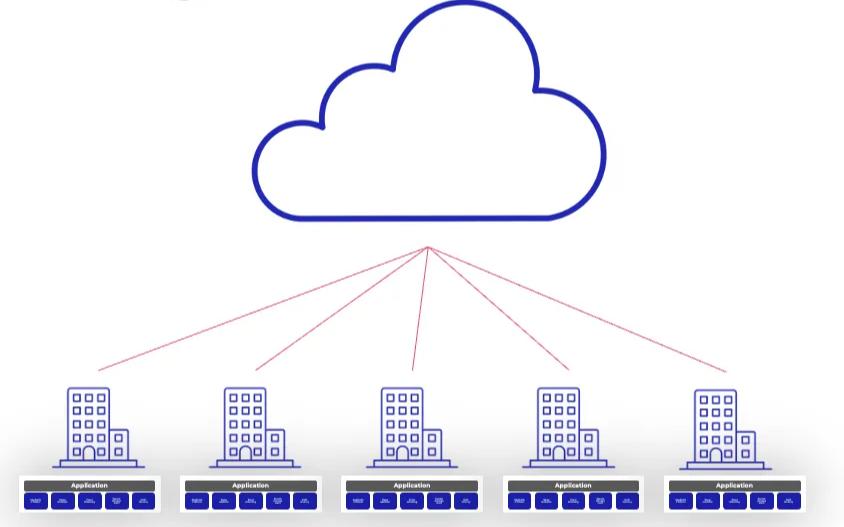
The takeaway is that edge applications must be self-sufficient. They need to have available all the cores services needed to operate even during prolonged disconnections. That means that the services need to be replicated and available on-site.
Designing Resilient Edge Infrastructure
Designing for this kind of resilience at the edge means rethinking how the infrastructure is designed to provide distributed services lock step with how applications are deployed.
- Container images must be pre-replicated across hosts where they run, to support failover in off-line scenarios.
- Secrets, credentials, and certificates need to be available locally, but only in locations where they will be used (i.e. alongside the applications that will consume them) to reduce the attack surface.
- All monitoring and health checks must operate within the site, keep local buffers of telemetry and logs, and make it available to the central dashboard based on distributed queries.
Site-Local Failover: How It Works in Practice
Let’s examplify using our system. When a node in a site-local cluster goes down, our local scheduler orchestrates a re-deployment of all applications on the distressed or offline host to healthy hosts within the cluster. For example, if a host running a business critical authentication service fails, it gets restarted on another node—completely autonomously and without involvement from the central Control Tower.

This means that, even in fully disconnected scenarios, the failover works. And more than that, all services required for the application to function well will be reachable on the site-local network.
It’s not just about uptime. It’s about continuity. Whether you’re selling groceries in a disconnected retail store or navigating a regulation-heavy marine environment, business must go on.
Final Thoughts on Building Resilient Edge Systems
Offline edge scenarios aren’t just rare corner cases. For many organizations, they’re the norm. Power outages, fiber cuts, or other types of unintentional disruptions are business as usual since infrastructure is managed by humans.
Designing for these moments isn’t just good engineering—it’s essential infrastructure.
- Design the infrastructure to make offline scenarios undramatic.
- Remember, applications require a multitude of services to function well.
- Keeping the services local (including fail-over) provides survivability.
So whether you’re running authentication at the edge, keeping POS systems alive in a retail store, or simply trying to survive the next upstream hiccup, the key is this: keep services local, design for failover, and always plan to stay alive. Despite that (well-intentioned) guy!