September 2023: Feature releases & highlights
Web UI for host maintenance, image download
The September releases contain:
- Enhanced site and host maintenance: edge sites are not constant, hosts need to be replaced, the OS needs to be upgraded and security incidents might happen. The Control Tower Web UI now supports actions to manage these areas.
- Enhanced container image management: edge sites might have unstable connections, which impact the image download performance. We have now enhanced the download function to be able to restore downloads from where it stopped rather than restarting.
Let us start with an overview of the site and host maintenance features.
Site maintenance
The site menu top right now contains the following new functions:
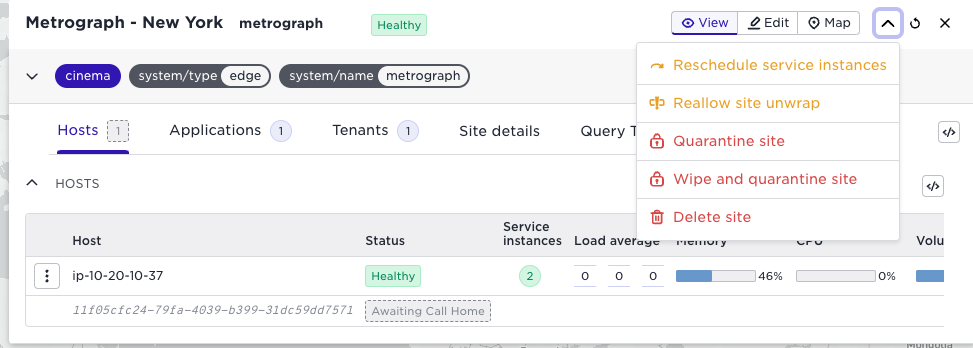
Reschedule service instances
Rescheduling service instances is helpful, for example, when you add new hosts to an existing site with running applications. Freshly added hosts will not have any workloads. The rescheduled action will spread service instances across the hosts on a site. Note, however, that it is defensive and will not strive towards a perfectly balanced situation; instead, it prefers to keep running services instances where they are. Assume you have a single host edge site like the one illustrated below:
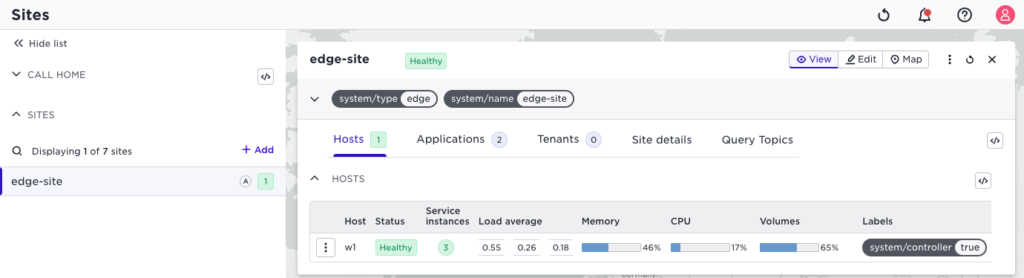
We have two applications on that site, one with two replicas, which results in three service instances in total. Note the service instances column in the host list above. This is an enhancement.
If we now add two hosts to the site, we get the following situation:
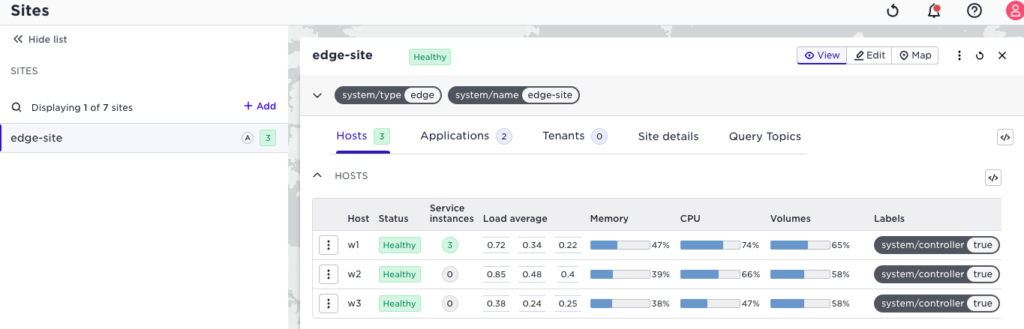
This is where the reschedule action is your friend. It will move service instances to the newly added hosts:
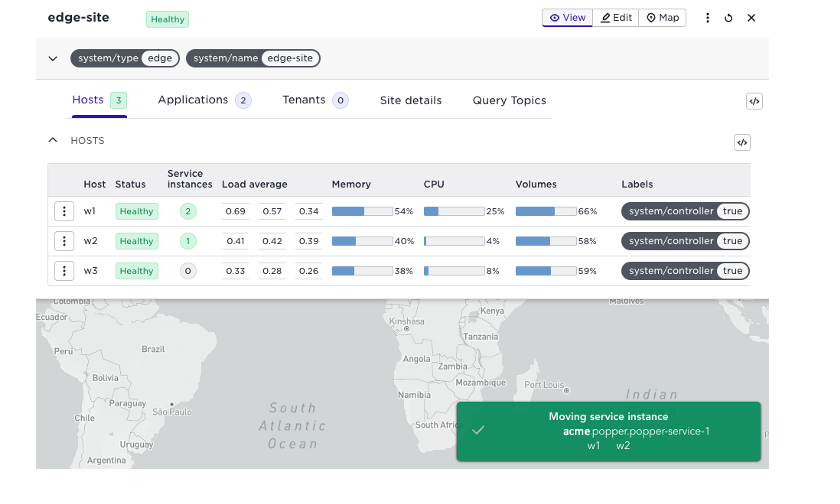
Consecutive calls to the reschedule action will further spread service instances.
Reallow site unwrap
When a site is first initialized, its bundle is unwrapped once. The bundle is the site’s unique secrets needed to establish clusters and communicate with the Control Tower. For security reasons, sites are not allowed to perform this operation twice. If you are sure that a site is trusted and know why the first unwrap failed, you can reallow this operation.
(Wipe and) Quarantine site
If you suspect a site has been compromised, you can use this action to secure any site’s local data. It will disable the entire site from connecting to the Avassa system. It will automatically rotate all sensitive keys for all tenants distributed to the site. You can optionally select to wipe all the data from the site if it is connected. The screenshot below shows a quarantined site.
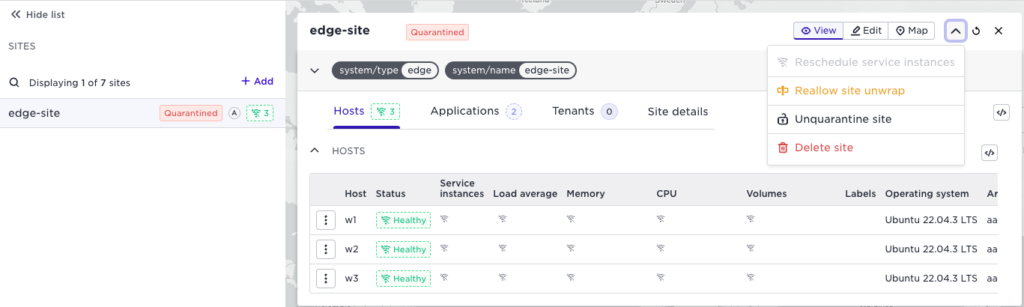
If you do not wipe the data, it can be unquarantined again to restore the site.
Host maintenance
New or enhanced functions for host maintenance are elaborated below.
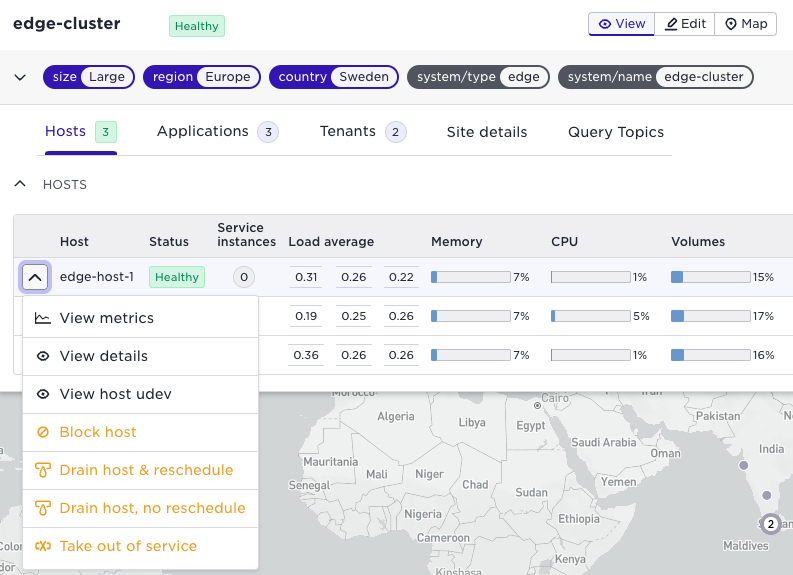
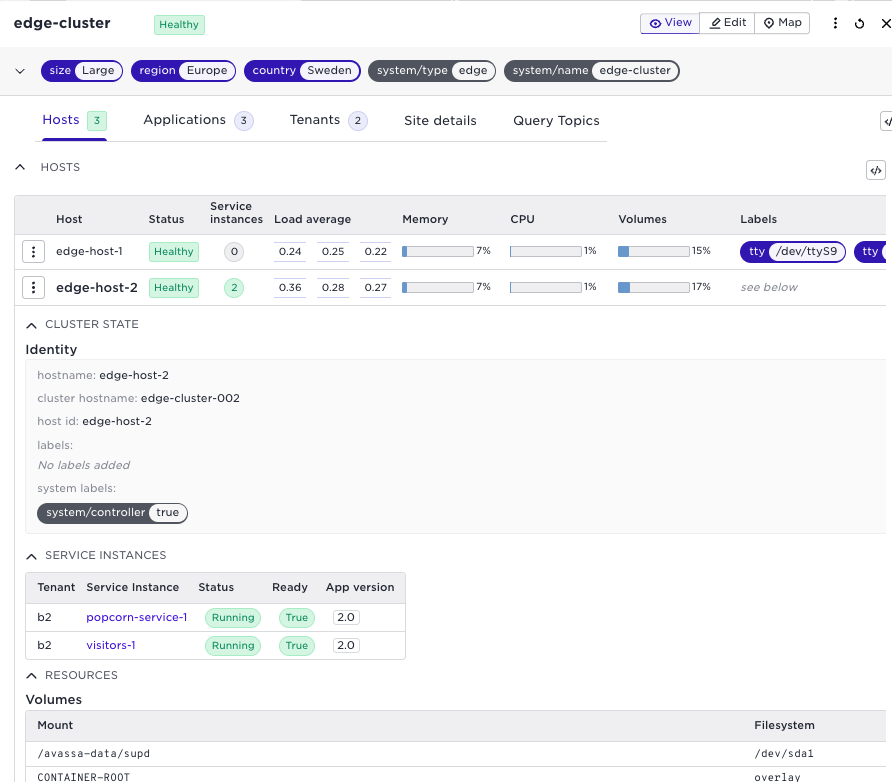
Enhanced host details view
The detailed view for host details has been restructured to enhance usability.
Each details category has an expand/contract feature so that it is easier to get an overview and see the relevant information. There is also a new section that shows which service instances that are running on that specific host. This is highly relevant when doing site maintenance and trouble-shooting.
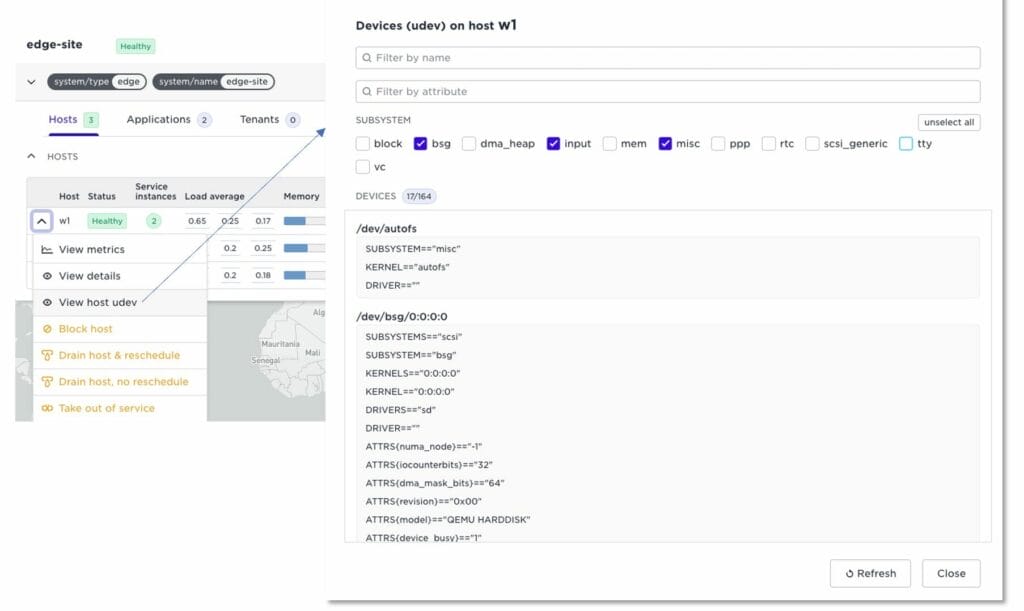
View host udev
udev is the Linux device manager. You can write device discovery rules that generate dynamic labels if corresponding devices are found on the host. This, for example, lets you write a rule that discovers a specific USB-connected camera on a site. An application developer can then require that camera for the container. Edge enforcer will automatically schedule the container to that host. Read more on device discovery.
We have now added a function in the UI to inspect devices on your hosts. This lets you inspect devices on your edge sites remotely. It is also a good tool when writing udev rules.
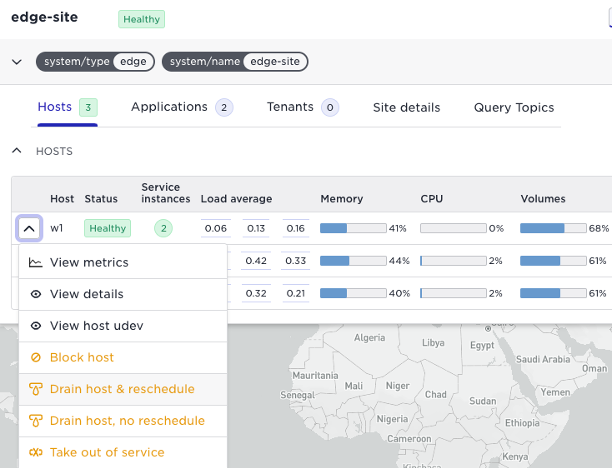
Host maintenance actions
Below is a list of the host maintenance actions
- Block host: this will block the system from starting services on this host. This includes preventing the system from moving services from drained hosts to this particular host. This is useful when you are draining several hosts and want to avoid services being scheduled to a host that you are about to drain.
- Drain host & reschedule: This will remove any services from this host and move them to other available hosts. Drain is helpful for example when upgrading the OS requires a restart. Other Avassa services, like Volga topics, will not be moved from this host.
- Drain host, no reschedule: this function will stop the services on the host but not schedule them to other hosts. This is useful if the restart is short and it is ok with application downtime.
- Take out of service: use this feature when a host is to be replaced. Out-of-service will move all Avassa services to other available hosts.
You can read more about site maintenance in our documentation.
Below follows a sequence when draining the host w1 which currently runs two service instances:
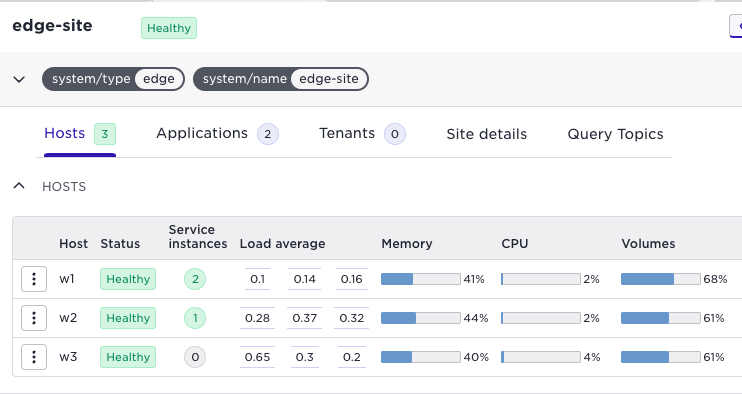
Pick the drain and reschedule action:
After the reschedule action, services have moved to host w2 and w3, and you are ready to, for example, upgrade and reboot host w1.
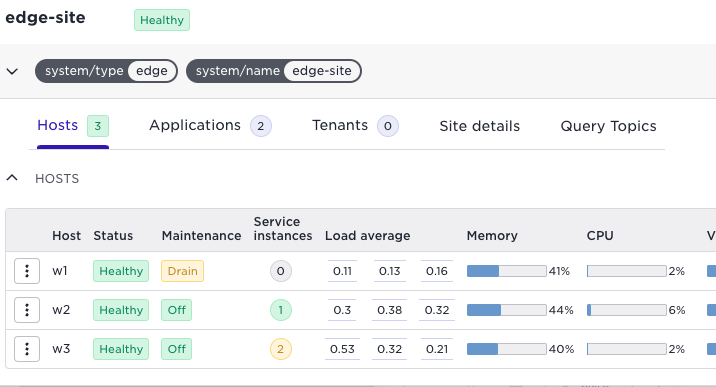
Let’s say you were about to do the same with w3 you could have blocked that host first, this would have put all services on w2.
Enhanced container image management
This is a good place to emphasize essential design decisions we have made around image management since day 1 of the Avassa system:
- A site may not have access to public registries for downloading images. Therefore, images are first cached into the Control Tower and then later downloaded from the Control Tower to the sites through the established secure connection.
- A site-local restart should not need to reach out again for the image. The Edge Enforcer has an embedded image registry that manages all needed images.
- Sites need to be able to perform local fail-over of applications within the cluster. Therefore, the images are replicated amongst the hosts on the site. If one host fails, another host can take over the application using the replicated image.
All the above enables site autonomy and does not require open outgoing connections.
Now, let us move over to what is new in this area.
Edge computing is characterized by limited and unstable edge site connections. Large image files could cause problems when the network goes up and down. Therefore, we have enhanced the downloads of images to sites always to try to restart a failed image download using the bits it has received so far (i.e., interrupted or bad internet connections should not cause a complete re-download of an image). The image download progress can now also be seen in the api and in coming UI releases.
The image replication and pulling mechanisms within a site have also been enhanced in several ways
- Edge Enforcers now internally manages the eventual need to fetch an image from another host. This removes the previous requirements to keep registry port 4848 open and to configure “insecure registries” of docker.
- image replication within the site is more efficient and resilient.
- enhanced support for pulling through proxy nodes.
Speaking about large downloads, I could not resist a time warp on spinners…
We prefer progress bars indicating how much is left in preference for spinners and hourglasses. Just learned the second category is called throbbers; check your thesaurus.
Sources claim that one of the first uses of a throbber was in the Mosaic browser where the NCSA logo was animated while downloading a page. (Wait, Xerox workstations, of course, probably first again). Netscape continued along the same path and animated its Netscape logo while downloading. Not to mention the Mac OS historic stopwatch and Windows hourglass. And now there is the spinning wheel, I wish I knew why.
With all this, I leave it as a cliffhanger for the progress bar in the next Avassa UI indicating large image downloads…

LET’S KEEP IN TOUCH
Sign up for our newsletter
We’ll send you occasional emails to keep you posted on updates, feature releases, and event invites, and you can opt out at any time.