A Simple Language for Placing and Scheduling Applications
You have a lot of hardware, distributed over many locations. If you want to deploy the exact same software, with the exact same configuration on all those machines with the exact same hardware, congratulations, this article is probably overkill for you.
Not all machines are the same
For our customers, there is generally never a 100% homogeneous environment where they need to deploy their applications. Some edge hosts have a connected camera, others have a GPU and others have not. When tasked with deploying an application that takes a video stream and processes that using the GPU, it is a must that the containers run on the correct hardware.
But if you have a heterogenous machine park, how do you keep track of which application container to run at what machine? You can of course keep an “offline” list with a edge host to device mapping, but this is both tedious to create/maintain and can be error prone.
💡 Definition: when we in this article say “device” we mean physical hardware connected to the compute host. In some contexts, this is called a leaf device. Examples can be USB cameras, serial devices, etc.
At Avassa we have taken a different path, you declare what types of devices your applications need and let the system identify those. You will then rely on our scheduler to place the correct container at the correct edge host.
💡 Definition: when we in this article mention the scheduler, this refers to the code that decides on what host or site a container or application should run. The scheduler factors in compute resources, e.g., memory and disk availability, but also the presence of devices.
Meet device discovery
In the Avassa system you declare what leaf devices you are interested in in the site configuration using Linux udev rules. Whenever the Avassa system detects a matching device, a dynamic label will be created on that host.
The YAML below is an extract from a real world example, where a lab host has a temperature and humidity sensor connected via serial (MODBUS RTU)
name: lab
type: edge
labels:
env: test
device-labels:
- label: sensor
udev-patterns:
- SUBSYSTEM=="tty",KERNEL=="ttymxc2"
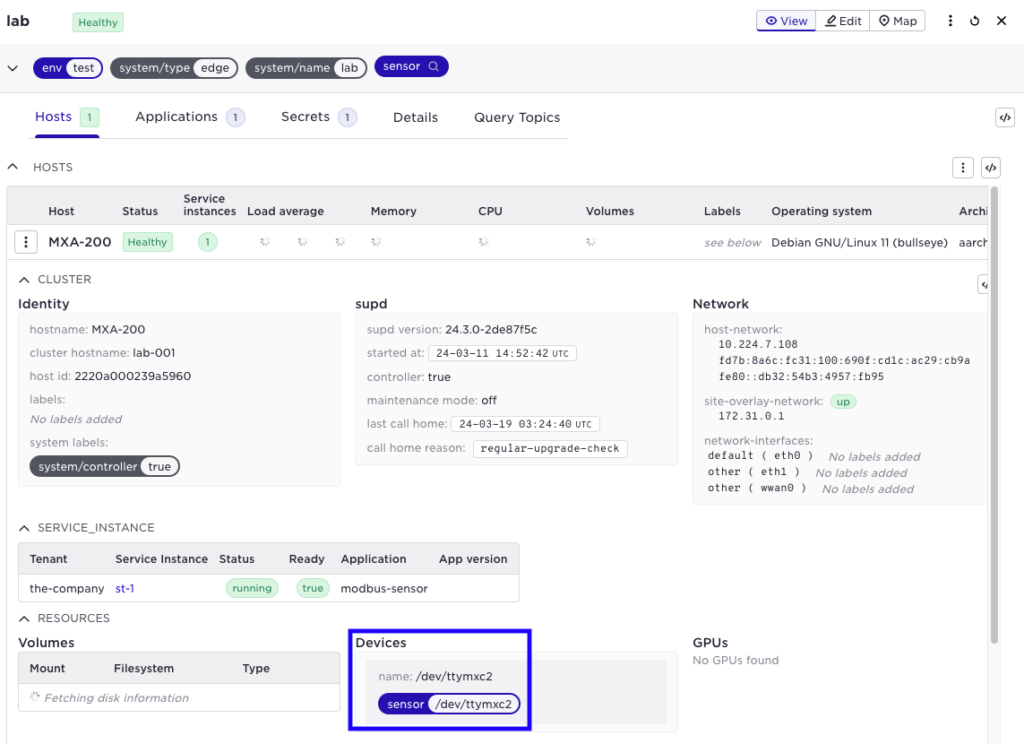
The result, as shown in our UI, the system has identified the correct device name /dev/ttymxc2 on host MXA-200
Another example used in our demos, the pattern rules are shown below:
device-labels:
- label: entrance-camera
udev-patterns:
- SUBSYSTEM=="video4linux",ATTR{name}=="entrance camera"
- label: checkout-camera
udev-patterns:
- SUBSYSTEM=="video4linux",ATTR{name}=="checkout camera"
- label: general-area-camera
udev-patterns:
- SUBSYSTEM=="video4linux",ATTR{name}=="general area camera"
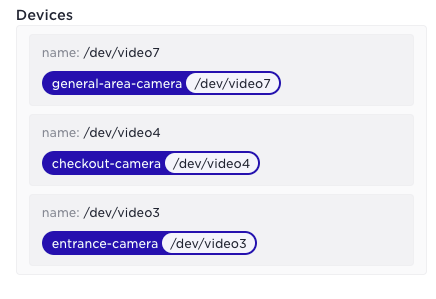
And the generated matching labels for a specific host in the UI:
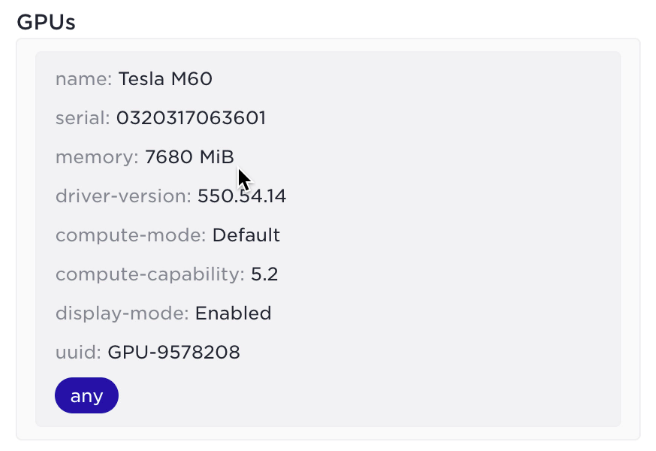
And GPUs in a similar fashion, in the example below we show a discovered GPU on a host that generates a label rule any
Application Device Access
With the process of discovering which hosts have what devices, how do you actually use these in your application?
When declaring your application specification, you add a couple of lines of configuration
name: modbus-sensor
version: "1.1"
...
devices:
device-labels:
- sensor
Note that the label sensor matches the expression in the site configuration above. This will instruct the application scheduler to run this particular container on a host where such a device is available.
Secondly, the application must get access to the device name, i.e., /dev/ttymxc2 in this example. This is done by creating an environment variable, in this case SENSOR_DEV. The SYS_HOST_DEVICE_LABELS[sensor] is expanded at runtime to the correct device name.
name: modbus-sensor
version: "1.1"
...
env:
SENSOR_DEV: "${SYS_HOST_DEVICE_LABELS[sensor]}"
Note, in no case do you need to know any hostnames or similar, you describe the application requirements and the Avassa scheduler takes care of placing the container on the correct hardware.
This gave an introduction to how application components are placed on individual edge hosts. But how do you get your application to the correct site/cluster?
Application Deployments
One option is of course to keep a list of exactly what edge sites each application should run, we at Avassa think you can do better.
Again we are recommending using site labels.

In this example I have configured a handful of labels, e.g., size, region, iot-central etc.
With these labels in place, when I declare where I want to run my applications, I will not explicitly list stockholm-cluster (although I can 🙂) but rather I use the labels:
name: image-classifier
application: image-classifier
application-version: "1.5"
placement:
match-site-labels: iot
deploy-to-sites:
canary-sites:
match-site-labels: iot-central
canary-continue-by-action: true
sites-in-parallel: 4
healthy-time: 1h
Let’s break this down a bit
placement:
match-site-labels: iot
This instructs the system I want to run the image-classifier application on all sites that have a label iot, this could be one or thousands of sites.
Next to get upgrading under control:
deploy-to-sites:
canary-sites:
match-site-labels: iot-central
canary-continue-by-action: true
The canary instructs the system to roll out new versions to sites having the iot-central label. canary-continue-by-action tells the system to pause and wait for human/API input to continue.
deploy-to-sites:
...
sites-in-parallel: 4
healthy-time: 1h
The last part instructs the system to roll out to the rest of the sites, 4 in parallell. The healthy time tells the system how long to wait after an upgrade before considering it a success. The healthy time can be set to 0 to indicate that a successful start of the application is enough to continue the rollout.
Conclusion
We strongly believe in adding abstractions to the application deployment language. Hardcoding hostnames or site names simply doesn’t scale when the numer of edge sites and hosts grow. We believe that labels in combination with discovery are the correct abstractions.